关于聚簇索引,非聚簇索引,主键索引,普通索引(InnoDB)
InnoDB中每个表一定会有一个聚簇索引
- 创建了主键,聚簇索引就是主键(ps:为了性能,正常情况下必须得有主键)
- 没有创建主键,聚簇索引是InnoDB选择的一个唯一的非空索引
- 既没有主键,也没合适的唯一非空索引,聚簇索引是一个InnoDB创建的一个隐藏的列,具体说是InnoDB会创建一个内部的、隐藏的row ID,并使用它作为聚簇索引。
非聚簇索引就是普通索引,可以在任意列上创建以加速查询。这种索引并不影响数据在磁盘上的物理存储顺序,因此被称为非聚簇索引。
存储引擎在索引上的重要区别
MyISAM
使用MyISAM存储引擎存储的表和表中数据的文件由三个文件组成: (/var/lib/mysql/)
.frm: 表的结构定义文件 .MYD: 数据文件 .MYI: 索引文件

主键索引与非主键的普通索引
在MyISAM中, 通过主键索引与非主键索引访问的叶子上存储结果,不是一条一条数据, 而是数据的物理地址
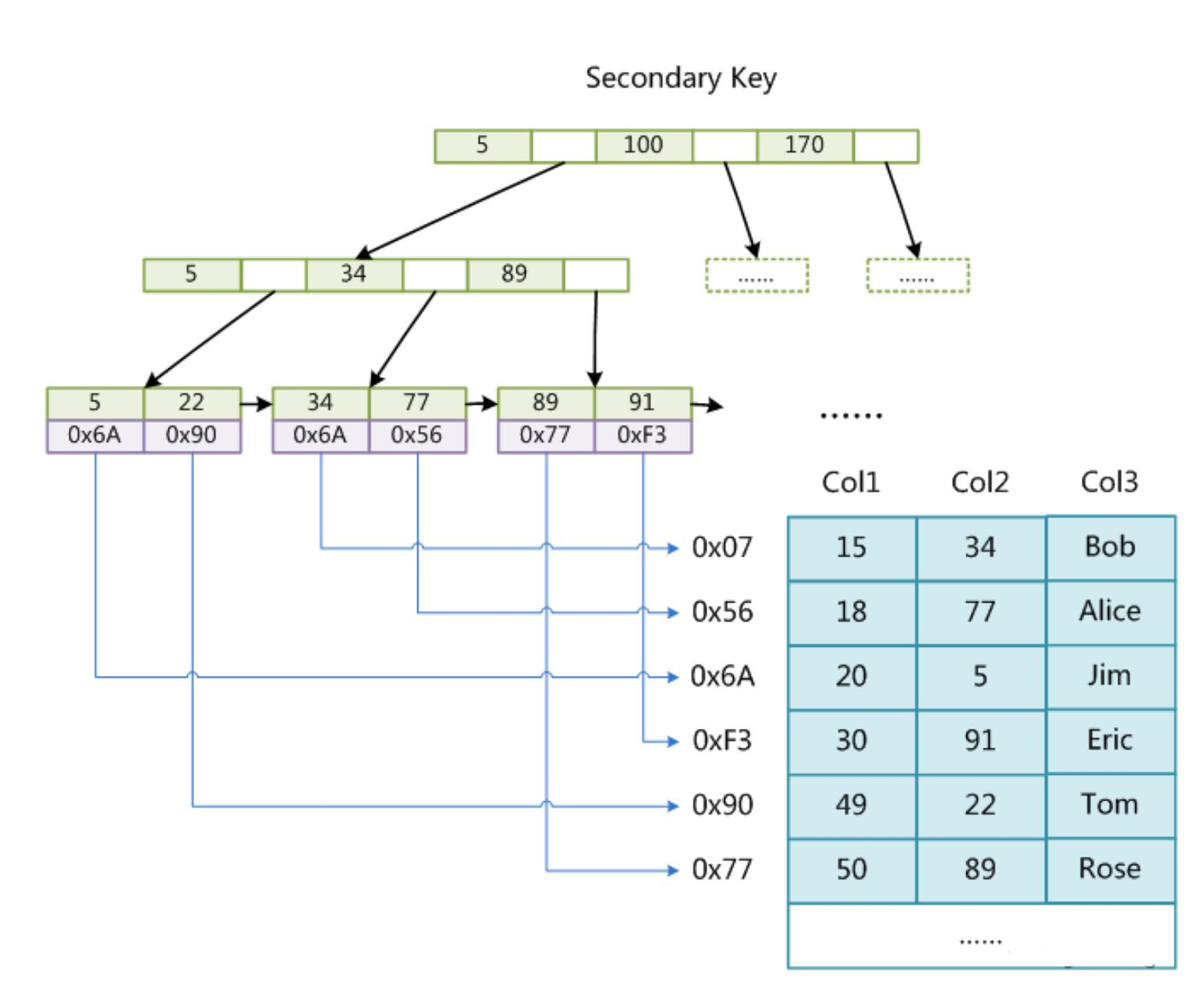
InnoDB
使用InnoDB存储引擎存储的表的文件由两个个文件组成:
frm文件: 表的结构定义文件 ibd文件: 数据和索引共用文件: 既包含索引, 又包含了具体数据

主键索引
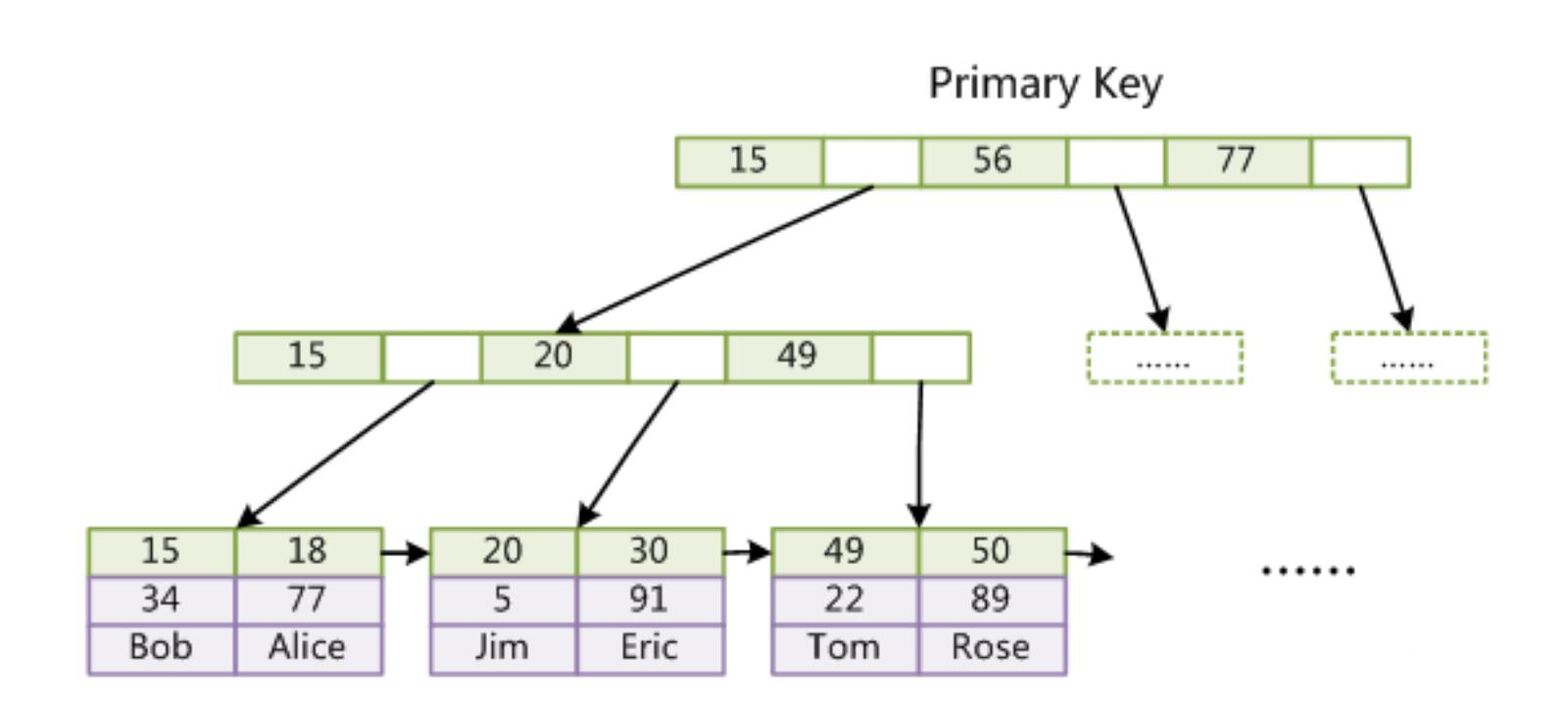
在InnoDB中 通过主键索引访问的最终的叶子上的结果, 是数据本身
非主键的普通索引
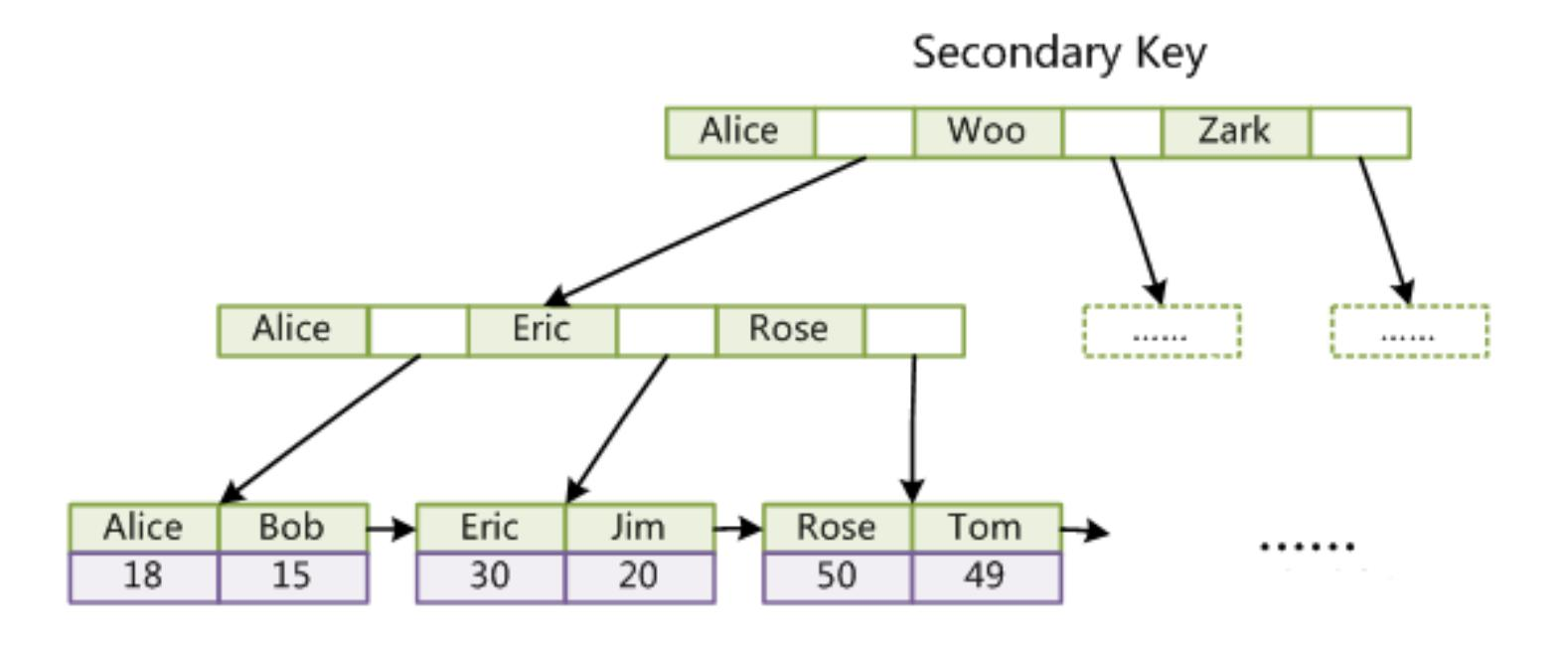
在InnoDB中, 通过非主键索引访问的叶子上存储的结果, 是主键索引的值
非聚簇索引需要用户主动定义, CREATE INDEX 自己定义个索引名 ON 表名(列名);
实际上非聚簇索引是是先找到主键值,再根据主键值去主键索引找到这个数据(回表)
索引延伸问题(面试重点)
1. 什么是聚集索引/聚簇索引, 什么是非聚集索引/非聚簇索引?
聚集索引:索引与数据是一起的,即InnoDB的特点
2. Innodb表中不建立索引/没有主动设置主键, 为什么要有默认索引? 默认索引是什么?
在Innodb中没有索引行不行?
不行,InnoDB中数据都是依赖于主键索引组织的,没主键便没法存储与组织数据了。
MyISAM倒是可以,因为它索引与数据是分离的
若没主动建立主键索引,InnoDB会自动生成一个6字节的不可见的ROW_ID的列, 作为默认的主键索引组织数据
3. 既然索引性能这么好,是不是一个表建立的索引越多越好?
no!
- 索引比较占用内存
- 索引较多时,增删改都可能导致索引结构的变化,效率急剧降低!
- 并不是每列都适合做索引
4. 那么什么列适合做索引呢?
重复度低的列(典型就是id),InnoDB使用的是B+树存储,如果重复度比较高,相同的值可能会分布在很多节点中,导致查找和排序变慢。
具体来说:如果索引列中存在大量重复的值(比如性别只有“男”和“女”两个选项),那么即使B+树能够通过大小比较快速决定往哪边走,但结果可能是延伸方向很多节点上都有相同的值。在这种情况下,B+树不能有效地利用大小比较来快速定位到特定的一个位置,因为任何一个路径上的多个节点都可能有相同的值。搜索效率就会降低,因为需要更多次的比较和检查。
使用率高的列。若一个列使用率低,作为索引不但没什么意义,而且在数据进行增删改的时候,该索引结构也会变化,降低效率
数据不会频繁变化的列。也是因为频繁变化则索引结构会经常重构
5. 什么时候创建索引呢?使用什么类型?
一般在建表时创建,一般设为int,且是auto_increment
6. 什么是回表?如何避免回表?什么是覆盖索引?
- 回表:是指数据库通过索引定位到符合条件的记录(但没查到数据)后,需要再从数据表中检索完整的行数据。这种操作通常发生在索引无法直接覆盖查询所需的所有数据时。
- 回表是针对InnoDB的。因为MyISAM直接存储了数据行位置,不用回表直接能找到。
避免或减少的方式:
使用覆盖索引:确保查询所涉及的所有列(包括
SELECT列和WHERE条件中的列)都包含在一个索引中。这样,查询可以完全在索引中完成,不需要访问数据表。选择性地创建索引:如果某些查询频繁使用特定的列,可以为这些列创建组合索引,确保常用查询可以直接在索引中完成。
使用合适的索引列顺序:在创建复合索引时,将最常用的查询条件列放在前面,这样可以增加索引的使用率并减少回表。
7. MyISAM和InnoDB的区别 (以及memory存储引擎)
物理存储文件不同:
InnoDB存储两个物理文件:结构,索引+数据
- MyISAM存储三个物理文件:结构,索引,数据
- memory:存储数据到内存上
索引结构不同:
- InnoDB支持B+树索引/hash索引(默认B+树索引)
- MyISAM仅支持B+树索引
- memory支持B+树索引/hash索引(默认hash索引)
事务支持不同:
- InnoDB支持事务
- MyISAM与memory都不支持事务
外键支持不同:
- InnoDB支持外键
- MyISAM与memory都不支持外键
锁支持不同:
- InnoDB不仅支持表锁, 还支持行锁
- MyISAM和memory仅支持表锁
InnoDB并发性能比较高/ InnoDB锁的颗粒度比较小
8. 什么情况下选择使用MyISAM?
MyISAM问题是增删改时,会锁定表,而且在读时还会阻塞写入,只有读不阻塞读,而InnoDB在增删改时只锁定行
- 不需要转账、充值、付款这种的业务的
- 一般为读数据较多的应用,读写两者都频繁的不适合,若是单单读得多,或写的多,都适合
- 并发访问相对低的业务
- 以读为主的业务:如官网,图库,用户数据库
什么时候使用memory引擎?
建议用Redis
9. 最左匹配原则
一个索引, 是有可能通过多个列组合而成的, 先以最左侧的列作为比较的依据, 如果一样, 再比较下一个字段
11. 全文索引
> MySQL中的全文索引, 是一种加速MySQL中字符串查询和匹配的索引机制. (比如类似搜索引擎这种数据存储的数据库比较适合使用)