数据类型
| MySQL的整数类型 | 占用字节 | 有符号 | 无符号 | 说明 |
|---|---|---|---|---|
| TINYINT(M) | 1 | -128 ~ 127 | 0 ~ 255 | 很小的整数 |
| INT/INTEGER(M) | 4 | -231 ~ 231-1 | 0 ~ 232-1 | 普通整数 |
| BIGINT(M) | 8 | -263 ~ 263-1 | 0 ~ 264-1 | 大整数 |
| MySQL的浮点数 | 占用字节 | 说明 |
|---|---|---|
| FLOAT(M, D) | 4 | 单精度 |
| DOUBLE(M, D) | 8 | 双精度 |
| MySQL日期 | 字节 | 日期格式 | 表示范围 |
|---|---|---|---|
| YEAR | 1 | YYYY | 1901 ~ 2155 |
| TIME | 3 | HH:MM:SS | -838:59:59 ~ 838:59:59 |
| DATE | 3 | YYYY-MM-DD | 1000-01-01 ~ 9999-12-31 |
| DATETIME | 8 | YYYY-MM-DD HH:MM:SS | 1000-01-01 00:00:00 ~ 9999-12-31 23:59:59 |
| TIMESTAMP | 4 | YYYY-MM-DD HH:MM:SS | 1970-01-01 00:00:01 ~ 2038-01-19 03:14:07 |
| MySQL字符串 | 内存占用 | 说明 |
|---|---|---|
| CHAR(M) | (M * 单个字符占用字节) | 固定长度字符串 |
| VARCHAR(M) | L+1字节 or L+2字节 。 | 变长字符串 |
| TEXT(M) | L+2字节 。 L: 0~216 | 变长文本字符串 |
| LONGTEXT(M) | L+4字节 。 L: 0~232 | 变长大文本字符串 |
- char可以正常存储字符串: “zs”, “我爱学习” ….(但一般char是为了存储类似性别这种具有固定长度和格式的短字符串,若不加长度,默认为1,这种定长字符串占用内存大小由设置的长度决定,而不是存储了几个字符)
- varchar不加长度会报错,这种变长字符串占用内存由存储了几个字符决定
创建表
CREATE TABLE 表名 ( 列名1 类型1 , ..., 列名n 类型n ) 表选项 分区选项;主键
CREATE TABLE table_primary1( id INT(11) PRIMARY KEY 可加上AUTO_INCREMENT, name VARCHAR(25), job VARCHAR(25), salary FLOAT, ); 或 CREATE TABLE table_primary2( id INT(11), name VARCHAR(25), job VARCHAR(25), salary FLOAT, PRIMARY KEY(id) ); 一般用作编号,所以该主键的一列元素不能重复且不能为null AUTO_INCREMENT是自增,数据增加一条该字段自动加一。在创建表后设置自增:alter table user modify id int auto_increment; ps:唯一键: - 可以为null - 用于确保表组合唯一 - 可以有多个唯一键修改表(没啥用)
alter table 表名 add column 列名 类型;
数据操作
增
INSERT INTO 表名 (列名1, …, 列名n ) VALUES (值1, … 值n);
更方便是values若按顺序排:insert into 表名 values(值1, ..., 值n);
INSERT INTO 表名 SET 列名1=值1, …, 列名n=值n;
数据中字符串和日期应该包含在引号中。
查
SELECT * FROM 表名 WHERE 条件 ;
SELECT 列名1, …, 列名n FROM 表名 WHERE 条件;
select实际上是决定查询结果将显示哪些列,如select a,sum(score) as b;就是显示a和b作为列标题
示例:select * from employee1 where id<20;
select * from 表名(或加个where 1);是查询所有数据
改
UPDATE 表名 SET 列1=值1 , 列2=值2 ,…,列n=值n WHERE 条件
> 如:update employee1 set job='老程序员' where salary >10000;
>
> 若不加where,则是对所有行的修改
删
DELETE FROM 表名 WHERE 条件
如:delete from employee; delete from employee where id=4;
- 若不加where,则是删除该表所有数据记录(但不是该表)
- delete只能删行为单元的数据,而不是只删某列
特殊关键字
Distinct
过滤重复数据,只返回其中一条给用户
SELECT DISTINCT 字段名 FROM 表名;Limit
对数据表查询结果集的大小,进行限定
SELECT 查询内容|列|* FROM 表名 LIMIT 初始位置,记录数目;
若不加初始位置,则默认为1。类似于偏移量的概念
As
为表和字段指定别名
内容 AS 别名
Order By
对查询结果排序
SELECT 查询内容|列等 FROM 表名 ORDER BY 字段名 不加排序模式: 升序排序 ASC: 升序排序.(ascending) DESC: 降序排序.(descending) 注意: 如上查询, 当我们进行多字段排序的时候, 会先满足第一个列的排序要求, 如果第一列一致的话, 再按照第二列进行排序, 以此类推.
Group By
对数据进行分组
```sql SELECT 查询内容|列等 FROM 表名 GROUP BY 字段名…
GROUP_CONCAT()函数会把每个分组的字段值都显示出来.分组时用。 group_concat(组内数据) 例如select gender, group_cat(age) … group by gender;打印 +——–+———————————-+ | gender | group_concat(age) | +——–+———————————-+ | 0 | 0000000000,0000000024,0000000024 | | 1 | 0000000052 | +——–+———————————-+
HAVING 用于分组,对分组后的各组数据过滤。(一般和分组+聚合函数配合使用),用于解决语法问题,即不允许先分组后过滤
聚合函数
一般用来计算跟列关的指定值. 通常和分组一起使用
| 函数 | 作用 | 函数 | 作用 |
|---|---|---|---|
| COUNT | 计数 | SUM | 和 |
| AVG | 平均值 | MAX | 最大值 |
| MIN | 最小值 |
-
COUNT:计数
SELECT 查询内容|列等 , COUNT (列|*) FROM 表名 GROUP BY HAVING COUNT 表达式|条件 COUNT(*): 表示表中总行数 COUNT(列): 计算除了列值为NULL以外的总行数 -
SUM:求和
SELECT 查询内容|列等, SUM(列) FROM 表名 GROUP BY 列 HAVING SUM表达式|条件 select class, group_concat(name), sum(chinese), sum(math) from students group by class; -
AVG:平均值
SELECT 查询内容|列等, AVG(列名) FROM 表名 GROUP BY 列名 HAVING AVG表达式|条件
SQL执行顺序
- select column_name
- from table_name
- where
- group by
- having
- order by
- limit
数据完整性
实体完整性,域完整性,参照完整性
实体完整性
一个表中每一条数据都应该是唯一的
通过设置一个主键实现
CREATE TABLE `students` ( `id` int(11) PRIMARY KEY AUTO_INCREMENT, `name` varchar(255) , `class` varchar(255) , `chinese` float , `english` float , `math` float ) ;
域完整性
保证表中数据字段取值在有效范围内,或符合特定的数据类型
即某一列数据存储类型要设计得合适。
参照完整性
确保相关联的表间数据要保持一致,就是避免一个表的数据修改了,导致另外个表的内容无效。通常是由外键(强有力)与主键维护的。
外键的设置;
- 创建表时:
CREATE TABLE `class` ( `id` int NOT NULL PRIMARY KEY, `name` varchar(20) NULL ); CREATE TABLE `student` ( `id` int NOT NULL PRIMARY KEY, `name` varchar(20) NULL, `class_id` int , CONSTRAINT `foreign_key_name` FOREIGN KEY (class_id) REFERENCES `class`(`id`) ); 格式: CONSTRAINT `外键名` FOREIGN KEY (当前表的一个列标题) REFERENCES `父表`(父表的一个列标题)
外键优缺点
优点:
- 限制数据的增删改,以保证数据的一致性。
缺点:
- 插入或删除子表数据,需要去父表中找对应的数据
- 删除或修改父表数据的时候,需要去检查子表中是否有对应的数据
- 影响性能,使用不便
多表
- 一对一
- n个表各自的数据,与其他表存在一一对应的关系
- 一对多
- n个表各自的数据,与其他表存在一对多的关系
- 如用户与订单;班级与学生
- n个表各自的数据,与其他表存在一对多的关系
-
多对多
-
需要一个中转表
- 订单和商品,一个商品可能有多个订单,一个订单可能有多个商品
- 剧本和演员,一个演员可能出演多个剧本,一个剧本可能有多个演员
-
数据库设计范式
第一范式:原子性
如设计地址时,不应该将字段设置为广东省广州市,而是使数据分离为原子,存储省份:广东;城市:广州
目的是适应之后的业务变化
第二范式:唯一性
即是一个数据须有唯一标识
通过设置主键来标识唯一的数据。
若不设置,得通过一个数据的各项信息来推断是否是某个数据,但不一定唯一。
第三范式:非厄余
多表通过一个主键标明一个数据,则不应该a表存了名字,b表也存这个名字,属于是没必要。
多表查询
查询结果是一个新的临时表
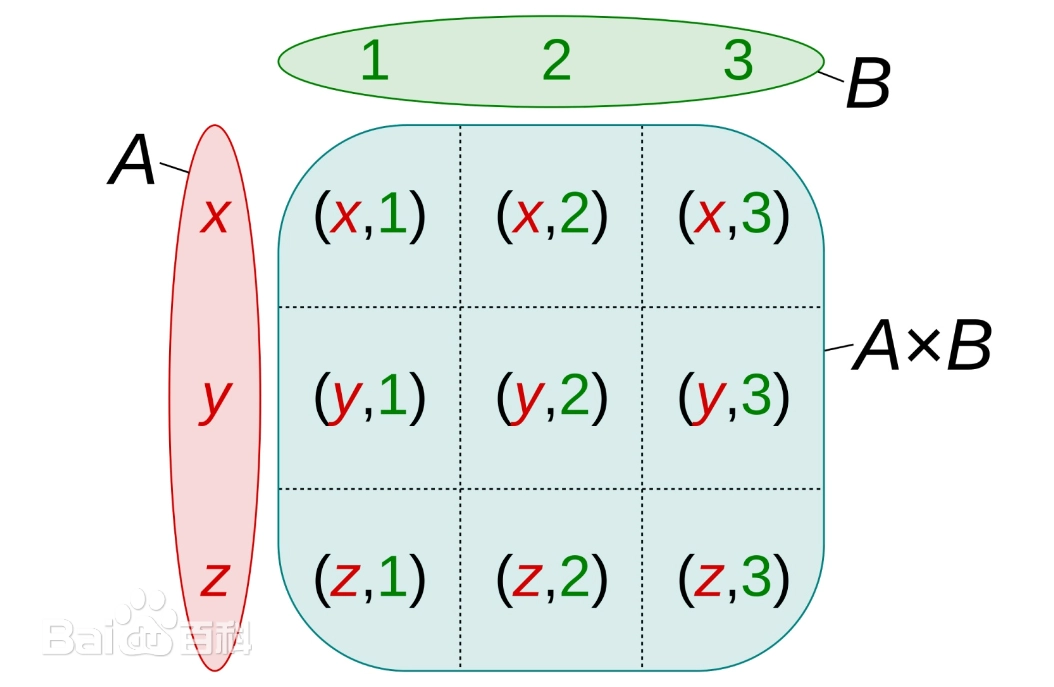
交叉链接
实则求多个表的笛卡尔积
若是直接 select * from 表1,表2,说白了就是把多个表的所有列拼在一起 常用: SELECT 字段 FROM 表1 CROSS JOIN 表2 WHERE子句
自然连接
没什么用,结果为有相同值的列
select * from student natural join class
内连接(常用)
SELECT 字段名 FROM 表1 INNER JOIN 表2 ON 子句 select * from student inner join equip on student.id = equip.student_id;
外连接
select 字段名 from 表1 left join 表2 on 表1.xx = 表2.xx; 左连接就是以表1为参照合并表2内容,类似是按表1排序,若表2没有跟表1匹配的,那么表1在对应位置填null
子查询
select在from或where后嵌套一个select
select 字段名 from 表|子查询 where <xx in|not in>或<exists|not> (子查询)
联合查询
合并重复数据行
select 字段名 from 表 ... union select 字段名 from 表 如: select * from score shere chinese >= 90 union select * from score where math >= 90;